



摘要:如果說2025年年初最火爆的AI話題是DeepSeekR1,那么近日橫空出世的「摩爾線程IPO」則為2025年的結束錦上添花,二者共同為中國AI科技創新開龍擺尾,向業內乃至國際傳遞了一個有力的信號
如果說 2025 年年初最火爆的 AI 話題是 DeepSeek R1,那么近日橫空出世的「摩爾線程 IPO」則為 2025 年的結束錦上添花,二者共同為中國 AI 科技創新開龍擺尾,向業內乃至國際傳遞了一個有力的信號:
中國的人工智能,從底層算力到上層模型,如果有需要,是有能力擺脫對海外技術的依賴、實現全國產自主自研的。
盡管這只是初具雛形——以 AI 芯片為例,華為、商湯等許多企業的實踐都已證明,國產芯片的性能較之英偉達等寡頭雖有不足,但通過軟硬協同的生態模式,也能用于 AI 大模型的訓練與推理。
摩爾線程于 12 月 5 日上市,作為「國產 GPU 第一股」,其上市首日股價就暴漲超 400%,上市五天后市值更進一步飆升至約 4500 億元、較發行時市值增長超過 7 倍——雖然市場占有率與技術先進性相比英偉達尤有不足,但摩爾線程 IPO 的這一亮眼成績,恰恰表明了市場在用腳投票,看好中國科技自主創新的未來。
不過,DeepSeek 代表的是國產 AI 在模型層的自主創新,而非從算力集群層與模型層的系統國產化創新。早前就有媒體報道,DeepSeek-R1 內部用于模型訓練與推理的算力集群主要基于英偉達 GPU、不采用國產卡。作為專注 AGI的 理想主義者與資源有限的創業者,DeepSeek 的選擇更符合對效率的追求,無可厚非。
然而,在 AI 技術發展道路上,需要有人追求智能的上限突破,也需要有人提前作進一步的考慮:除了模型層的自主可控,底層架構、算力乃至上層產品與應用也需要自主可控,并且還要性能趕超。R1 之后,中國 AI 發展的下一個步該往哪去?
再次走到十字路口,“我們需要用創新來打破當前的技術發展瓶頸”,這是商湯科技聯合創始人、首席科學家林達華給出的答案。
市場上能夠洞察趨勢的人很多,但真正有實力、有膽量并付諸行動的則屈指可數。作為少數者,商湯已經沖在 AI 底層創新與國產化的第一線。
一、算力是開始
如果細心觀察,大家不難發現:在主攻 AI-Native 的企業里,商湯是唯一一家同時在模型與算力上均有出色成果的公司。
BAT 之列的互聯網大廠雖也是全面開花、既有云又有模型,但終究不是 AI Native 的思維方式——這在短期的市場競爭里并不構成阻力,事實也多有證明;然而,在更大的技術愿景面前,如系統性的 AI 國產化面前,從底層到上層的技術研發、產品、應用乃至市場運營等各個角色的 AI-only 思維,則更有優勢。
這種優勢體現在:本土的AI 公司本就以開拓中國人工智能科技自主創新為起點與終局,「AI 國產化」的需求與他們的創業使命跟努力方向自然高度吻合。當內在動力與外部需求達成一致,兩股力量扭成一股力量,那么終局的實現就只是時間問題。
以商湯為例。其在 2020 年開始率先投入大裝置的決定,便是基于對 AI 算法需求的深入了解,深諳 AI 模型與底層計算基礎設置協同適配的重要性。這一前沿舉措雖曾在中途歷經質疑與低谷,但技術的發展規律最終驗證了其正確性。
也是基于對技術發展的前瞻認知,商湯大裝置并不止步于打造純英偉達 GPU 的算力集群,而是積極擁抱國產芯片、推動模型與國產芯片的全面適配,打造從模型到算力的多方位自主可控護城河。這是技術發展的兩大客觀要求:
一方面,模型與應用的迭代日新月異,速度與性能都是決定市場競爭的重要因素,若支持底層模型訓練與推理的「算力開關」掌握在不可控的競爭對手中,那么無論算法再怎么發力也是無濟于事,國產 AI 的整體競爭力仍會處于巨大的不確定性中;
另一方面,算法與應用的發展速度超過單一芯片廠商的流片速度。除了語言大模型,多模態大模型、具身智能、空間智能等等新興技術方向的成果層出不窮,即使英偉達的 CUDA 軟件生態壁壘再高,下游模型與應用廠商也必須依賴更多元的芯片供應。此外,生態不完善也是國產 GPU 發展的一大瓶頸,國產模型廠商與國產芯片廠商的合作幾乎是水到渠成。
就在今天,商湯與寒武紀剛剛聯合發布了最新合作進展,并一口氣宣布了未來深度優化的全套方案與打法。這也是雙方今年10月簽署戰略合作協議以來,在推進軟硬件聯合優化上的關鍵一步。
尤其在多模態生成模型領域,商湯日日新 Seko 系列模型已完成對寒武紀芯片的適配,包括其最新發布的行業首個多劇集生成智能體 Seko 2.0。配合商湯行業首創的LightX2V視頻生成推理框架,未來國產芯片將能支持真正意義上的實時視頻生成,為國產視頻生成產業創新發展提供自主的底層支撐。
根據規劃,在適配完成后,商湯和寒武紀還將在模型核心能力優化、提升算力利用率與成本效率、強化大規模并行處理能力與資源管理機制等多個方向進一步協作,為 AGI 接下來在多模態領域的創新提供可能。
同時,再以商湯與摩爾線程的合作為例。摩爾線程能提供全功能 GPU,兼顧 AI 計算與圖形渲染。商湯的大模型訓練需要極致的浮點運算能力,AIGC 視頻生成等應用與空間智能等前沿技術的探索又需要強大的渲染能力,摩爾線程等國產芯片正好符合現實需求。
而對國產芯片企業來說,商湯的日日新大模型體系、大裝置 SenseCore及廣泛的落地場景提供了絕佳的規模化場景驗證平臺,幫助它們驗證其 GPU 的性能、打磨產品。比如,在與摩爾線程的合作中,國產 GPU就首次在千億參數級的大模型訓練與推理任務中接受了工業級標準的嚴苛考驗。
除了寒武紀與摩爾線程,商湯還也與沐曦、華為、璧仞等幾乎所有國產芯片都進行了全面適配。
此外,商湯在擁抱國產芯片與硬件上取得的成就還有很多,包括全國首個完成與華為昇騰 910C 384 超節點的全面適配。華為昇騰 384 超節點通過高速互聯,將CPU、NPU、DPU、存儲和內存等資源全部互聯和池化,實現了更大的算力密度和互聯帶寬。商湯大裝置與華為合作,在調度優化、跨 POD 訓練穩定性與多維度故障檢測與恢復等問題上取得了多項攻關,有效解決了大模型訓練中的算力協同與通信效率問題。
今年 7 月,商湯還聯合華為、海光、寒武紀、庫帕思、摩爾線程、曦望Sunrise、壁仞科技、麒麟軟件等十余家國產芯片生態伙伴,共同發布了「商湯大裝置算力Mall」,幫助行業客戶在「算力市場」中以更低的門檻和成本,獲取經過驗證的高性能國產芯片,并實現自主安全可控:
在算力層,「商湯大裝置算力 Mall」可以提供高效穩定且具有成本優勢的異構計算基礎設施;在語料層,庫帕斯等提供高質量數據集、數據清洗、標注及合規安全的管理服務,提升模型訓練的數據源質量;在算法層,商湯「日日新」系列基礎模型與「大裝置 AI 應用開發底座」等 MLOps 工具結合,能夠幫助客戶快速完成模型微調和二次開發能夠解決實際業務問題的模型。
從算力到模型、再到應用的全國產化,是一個需要兼具技術實踐與前瞻洞察的愿景,也是行業的發展共識——「能否全國產化」與「是否要國產化」是兩回事,在后者之前、我們首先要實現前者。商湯并非 AI 賽道中唯一看到這個方向的玩家,但既有心、又有力去做這件事的企業鳳毛麟角。
作為少數的 AI 上市企業,商湯用行動與魄力表明,它已在「AI 國產化」這條路上出發。
二、系統化是終局
如果說模型與國產芯片的全面適配,只是國產化的起點,商湯「AI 國產化」戰略的成敗關鍵,在于模型底層架構創新與產品落地上。
從數據的角度看,通用人工智能的發展此前經過了兩個關鍵范式的迭代階段:第一階段是 Scaling Law,通過在預訓練階段擴“大力出奇跡”,用海量數據去訓練,提升 AI 模型的智能水平,如 GPT-3 及后續海內外多個大規模預訓練語言模型;第二階段是通過高質量的指令微調(SFT)、人類反饋強化學習(RLHF)等后訓練,將真實人類用戶的反饋給到模型,讓它能聽懂人類指令。當 Scaling Law 瓶頸突現,AGI 的下一個突破成為所有從業者的共同扣問。
在這里,業內有兩個方向:一是從后訓練突破,如 DeepSeek R1 在后訓練強化學習階段的創新,用可驗證獎勵強化學習(RLVR)挖掘模型邏輯潛能;另一個方向則是從模態突破,將通用基礎模型從單一的文本擴展到語音、圖像、視頻等模態。視覺積累深厚的商湯無疑堅定地踐行后者,而這一方向的一大瓶頸是能支撐原生多模態大模型的架構。
圍繞這一瓶頸,商湯在不久前發布并開源了自主研發的多模態模型架構 NEO,為其日日新大模型提供了新的架構基石。此前,業內雖也有多模態大模型架構,但大多采用「視覺編碼器+投影器+語言模型」的模塊組合,本質上仍然以語言為中心,限制了多模態大模型「智能涌現」的潛力。
作為多模態大模型的先行者,商湯沒有囿于老思路,從 2024 年就開始在國內率先嘗試突破多模態原生融合訓練技術,以單一模型在 SuperCLUE 語言評測 和 OpenCompass 多模態評測中奪冠,并基于這一核心技術打造了日日新 SenseNova 6.0。之后,商湯在 2025 年 7 月發布的日日新 SenseNova 6.5 通過在多階段的早期融合突破,大幅輕量化視覺編碼器,又把多模態模型性價比提升 3 倍。
近日,其發布的 NEO 架構又展示了更大的能力:在測試中,NEO 架構僅需業界同等性能模型 1/10 的數據量(3.9 億圖像文本樣本),就能開發出頂尖的視覺感知能力,在多項視覺理解任務中追平 Qwen2-VL、InternVL3 等頂尖多模態模型,在 MMMU、MMB、MMStar、SEED-I、POPE 等多項公開權威評測中斬獲高分。
繼 NEO 架構等原生多模態訓練技術的探索后,商湯在空間智能模型 SenseNova-SI 上取得優異表現,不僅超過了 GPT-5 甚至最新的 Gemini-3 Pro,而且也超過了李飛飛團隊最新發布的空間智能專用模型 Cambrian-S。
除了多模態模型的等底層技術創新,商湯開源的行業首個能夠做到實時視頻生成的推理框架——LightX2V,相關模型已累計下載超過 350 萬次,這一項目極大促進并完善了視頻生成的國產化生態。
LightX2V 框架設計了強兼容的國產化適配插件模式,可快速完成各類國產硬件的適配,包括寒武紀、沐曦、海光 DCU、昇騰910B等多款芯片。并且從測試數據來看,在不同 GPU 硬件環境下,LightX2V 均能實現高效推理,為不同場景的落地提供了靈活支撐。
實際上,大模型產品的規模化應用落地,尤其以視頻生成模型為典型代表,其目前最大掣肘是成本。拿關注度很高的AI短劇為例,通常生成 1 分鐘高質量視頻就需要 1 小時八卡的英偉達最新 GPU 計算,成本非常高、大規模落地幾無可能。而傳統的開源模型每小時計算只能生成 20 秒視頻,好一點的商用模型可以生成 80 秒。
而最新報告顯示,使用SekoTalk——商湯開發的實時語音驅動數字人技術,同樣質量的視頻,一小時計算可以生成1280秒。甚至在針對對話場景進一步優化后,使用消費級 5090 顯卡計算一小時,生成時長甚至可以達到 4500 秒。
值得注意的是,在本周舉行的商湯產品發布周上,商湯的 Seko、小浣熊等產品都將全面支持國產化。
隨著國產硬件與 AI 模型等的深度融合,將牽引國產化產業鏈上下游企業協同創新,為信創、數據安全要求及本地化部署,提供自主可控的關鍵解法,降低對海外技術的依賴。
從底層國產算力適配,到中間模型架構算法的自主創新,再到上層應用部署的安全可控,商湯在 AI 國產化不只是單點出擊,而是進行了系統性的全面布局,在每一環都有深入參與。
國產化不是唯一路徑,卻是不可或缺的選擇。在這場“必須要打的仗”面前,一個行業領頭羊的擔當絕不能是回避,而是要推動原始底層創新,并且迎難而上,聯合行業與生態的力量——商湯在做的,恰恰就是這樣一件事。

商湯集團股份有限公司(" 商湯集團 " 或 " 公司 ",股份代號:0020)今日公布截至 2025...
 2025-08-29
2025-08-29

(2023年7月17日,上海)生成式AI火爆全球,國內外AI大模型日新月異,人工智能加速走進日常生活...
2023-07-17

不僅是ASKO對斯堪的納維亞經典設計理念的當代詮釋,更標志著這個誕生于 1918 年的百年品牌,在堅...
2025-09-09

全球投資者歷來對貴金屬情有獨鐘,而如今以黃金為代表的貴金屬投資已經不僅僅局限于各種實物的產品,一些電...
2025-09-08


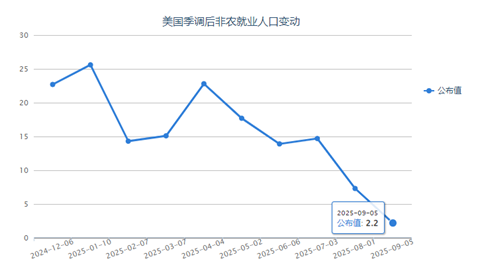
北京時間9月5日20:30,美國勞工統計局公布的數據顯示:美國8月非農就業人口增加2.2萬人,預期7...
2025-09-08
投資家網(www.hbzbj.cn)是國內領先的資本與產業創新綜合服務平臺。為活躍于中國市場的VC/PE、上市公司、創業企業、地方政府等提供專業的第三方信息服務,包括行業媒體、智庫服務、會議服務及生態服務。長按右側二維碼添加"投資哥"可與小編深入交流,并可加入微信群參與官方活動,趕快行動吧。

投資家網(http://www.hbzbj.cn/)隸屬于北京微金科技有限公司,是國內知名的資本與產業創新綜合服務平臺。平臺聚集數百萬優秀創業者、資深PE/VC、投資銀行家、上市公司及實業高管、專家學者等,致力于構建起資本、產業與政府之間的橋梁與生態服務體系。
郵箱:bp@wefinances.com
微信:yangqin6060
微信:15201337588






Copyright ? 投資家網 | 京ICP備16014291號-1 | 京公安備11010502031933號網站地圖![]()

微博

微信公眾平臺













